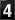
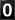
 accesses since February 5, 2003
accesses since February 5, 2003 copyright notice
copyright notice
 link to published version: Communications of the ACM, April, 2003
accesses since February 5, 2003
link to published version: Communications of the ACM, April, 2003
accesses since February 5, 2003
INTRODUCTION:
The technique of "anonymizing" network traffic has existed for many years. In it's most basic form, an 'anonymizer' is the combination of software and some network appliance (server, router, gateway) that redirects network traffic in such a way that the primary functionality is preserved while all identifying characteristics of the traffic that might enable a network analyst to trace the traffic back to the original source is removed. In practice, anonymizing is associated with both Web and email network activity, although in the latter case the term "remailer" is usually used to describe the process. However, in principle any network traffic, and any network protocol, can be anonymized.
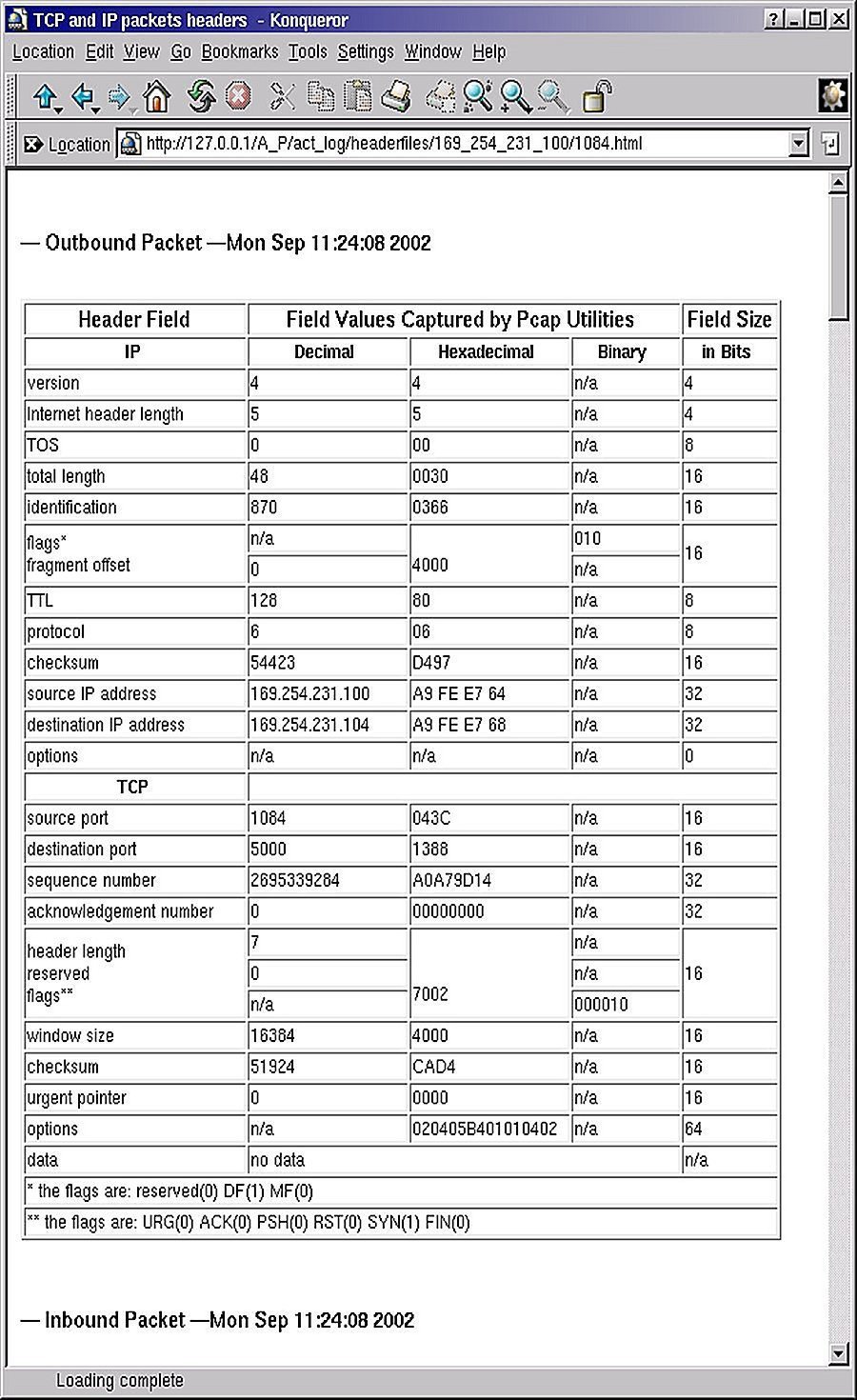
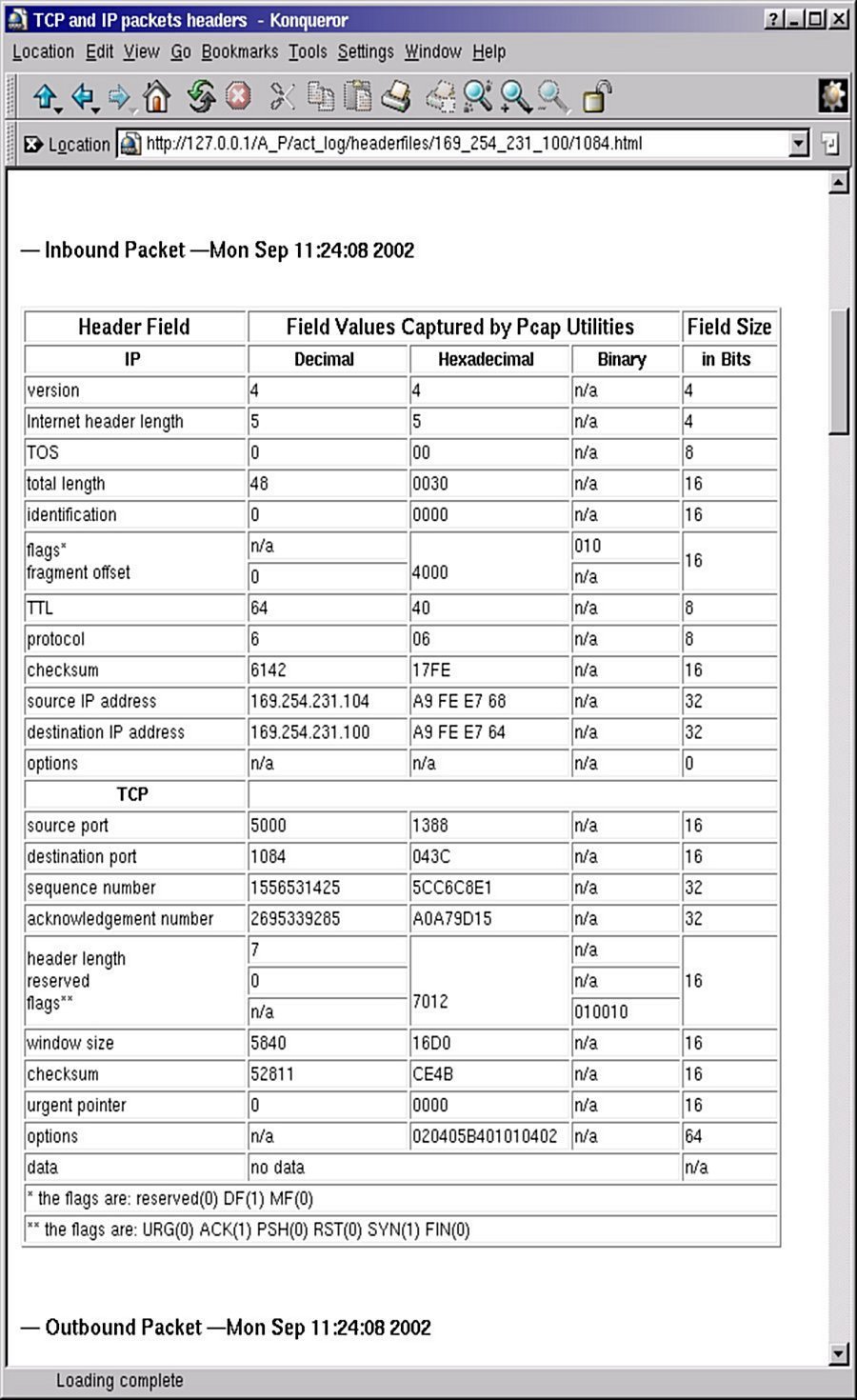
The general practice of anonymization can be easily described by reference to a typical IP packet. Figures 1 and 2 reveal the contents of two TCP/IP packets from the point of view of an Internet client. Figure 1 is the outbound packet to the server (or 'anonymizer'), and Figure 2 is the inbound packet from the server (or 'anonymizer'). The connection between the SYN in Figure 1 and the ACK in Figure 2 is evident from the sequence numbers.
|
Figure 1: Outbound TCP/IP packet from Internet |
Figure 2: Inbound TCP/IP packet to Internet |
A very brief analysis of some of these fields should prove helpful in the discussions below.
Version number field. Currently, most Internet traffic is Version 4 as in these cases. Its high-bandwidth offspring is Version 6 (aka, IPv6) that is being deployed, as you read this, on Internet 2.
Internet Header Length field denotes the length of the packet header in 4-byte words before the actual packet payload begins. In this case, the header length is 5x4=20 bytes, which is the typical IP header length. The payload of the IP header in this case is the TCP packet of 28 (48-20) bytes.
The Time to Live field contains the number of hops left before the packet expires, in this case 128 in the outbound packet from a Windows 2000 client, and 64 in the inbound packet from the Linux server/anonymizer. The idea is to terminate lost or errant traffic by decrementing the TTL by 1 every time a packet passes through a network router or gateway. Different operating systems have different initial TTLs, so this can be an identifying piece of data.
Protocol field designates the IP protocol that defines the contents of this packet's payload. 1 is ICMP, 2 is IGMP, 6 is TCP, 17 is UDP, and so forth, for the scores of available protocols. In this case, the protocol is 6 (TCP).
Source IP address field specifies the IP address of originating computer. Obviously, a dead give-away of the source. In this case, the IP addresses are internal and non-routable, since the traffic is on one of our experimental networks using our own proprietary 'anonymizer' called Anonymator.
Within the TCP packet, we have additional information that is useful in characterizing and identifying the network traffic. Such fields as source port, destination port, sequence number, the flag fields, window size, and "options" data can all be used for host and destination identification by those who analyze the network traffic and packet contents. The point to this discussion is that anonymizing Internet traffic requires modification of these fields in such a way as to simultaneously (a) achieve the intended effect of the connectivity, and (b) prevent anyone who might analyze this traffic from identifying the source or, in some cases, the destination. Even armed with the most simple tools - e.g., ARIN registry, Whois - one can associate an IP address with a domain name and a contact person. So, as far as the packet headers are concerned, anonymization means sanitization.
Figure 3 illustrates the process. In this case, the anonymizer, Anonymator, is of our own design. This screen shot is read in the following way: The top row is a packet summary of the traffic as it enters (left) and exits (right) Anonymator to enter the Internet cloud. The bottom row is a packet summary of the returning traffic from the Internet as it enters (right) and leaves (left) the anonymizer to return to the client. Visual inspection confirms that the referrer HTTP field in the outbound packet from the client was one of our university Web pages, while the OS field identifies the client OS as some variation of Windows NT, and the IP address is 169.254.231.100. However, after the Anonymator's sanitization, the outbound packet IP address has been changed to 169.254.231.104, while the active Web page became www.whatsanattack.edu, and OS ID was changed to Widget 2.4. Although much simplified, this illustrates the general principle.
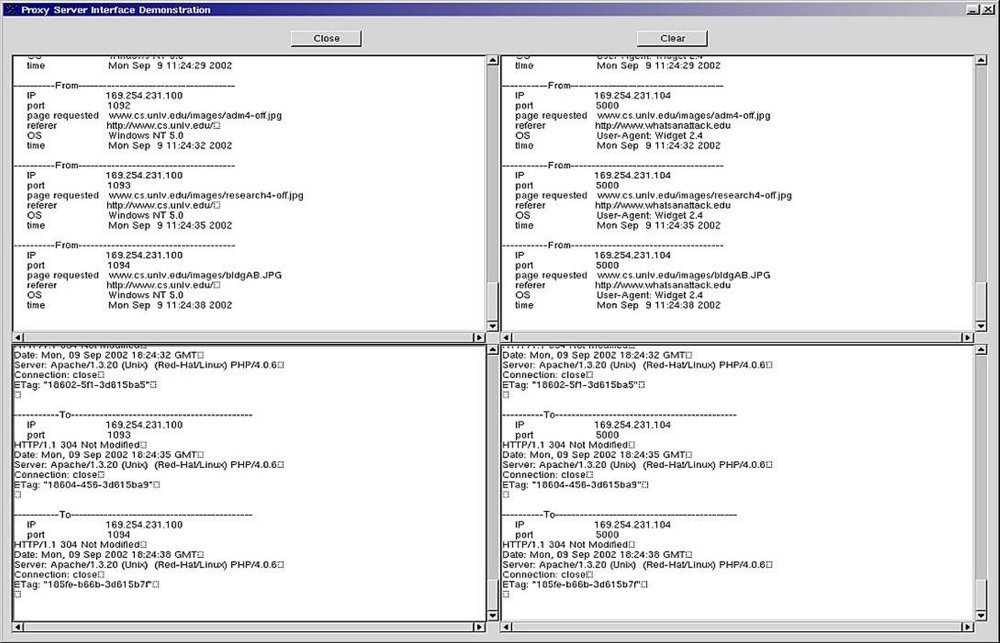
Figure 3: An illustration of packet Anonymizing: A screen shot from Anonymator.
So if one should want to anonymize traffic, the starting point is to change the source IP address, modify the TCP port address, change the TTL values to inhibit OS fingerprinting, maybe "bend" the protocol to escape monitoring, and so forth. That's the starting point of what has become the practice of "Anonymizing the Internet."
MOTIVATION
Like most everything in life, anonymization may serve good and evil. On the positive side, anonymization may ensure privacy and anonymity in support of free speech and the support of politically unpopular positions. On the negative side, it may enable such illicit or unauthorized network behavior as the downloading of pornography, using institutional email for personal use, and so forth. How might this work?
Consider the case of surfing the Web. Corporate and institutional firewalls are all capable of logging and filtering both inbound and outbound Web traffic by IP address, domain name, content, etc. In this fashion, it is fairly easy to ban or censor Internet traffic. How would an 'anonymizer' change that?
The answer is that the anonymizing service becomes the man-in-the-middle. Under one design, all traffic between the client browser and the 'anonymizer' could be encrypted, thus concealing the types of identifying information discussed above. We would presume that this outbound encrypted communication would be unreadable, even if noticed. The packet (aka communication) would be decrypted at the anonymizing server, whereupon the Web connection specified by the client would be directed to the target server. The resulting downloads would, in turn, be re-encrypted by the anonymizing server and sent along to the client. From the point of view of the client institution's firewalls, the only irregularity would be the presence of encrypted traffic, but the contents would indiscernible.
What is there to gain by anonymizing this Internet traffic? In short, the anonymization can hide a variety of information, including:
· URLs
· Navigation history
· The nature of downloaded content
· What browser is being used
· Source IP Addresses
· Operating Systems
In short, the Web communication can be sanitized to prevent tracing the traffic beyond the 'anonymizer' back to the originating client. This capability carries with it significant societal implications. Were it to be used to prevent the target server from depositing cookies on our hard drive, we may argue that anonymization is a social good. Were the very same service to be used to foster the formation of hate groups, download pornography to minors, or support terrorism, we would likely have the opposite reaction. The point we wish to make here is that society should be investing much more energy thinking about this issue.
THE ANONYMIZING LANDSCAPE
Anonymizer.com is the one of the first, if not the first, 'anonymizer' developed for the Web. Originally developed by Justin Boyan in the summer of 1995 and tested at Carnegie Mellon in the fall of 1995, it was later software licensed to C2net in 1996 then sold to Infonex in 1997. Infonex then extended the technology to remailing with MixMaster.
Anonymizer.com is now one of the largest and most popular online privacy services. It offers both shareware and commercial versions. Anonymizer.com's operation is faithful to the general description, above. As packets are passed through Anonymizer.com's servers, the packet headers are sanitized of information that may identify the source of the HTTP request. In its most basic form, only the URL of the request is encrypted the public-key encryption scheme, Blowfish. In this way, the request http://www.porn.com/ would appear as outbound traffic from the originating client as http://www.anonymizer.com/ciphertext, where ciphertext would be the encrypted form of the target URL.
This approach to anonymization is mature and stable. Unfortunately, it relies heavily on trust - trust in the fact that Anonymizer.com will neither maintain nor release privileged information, and trust that third party attacks (e.g., via session hijacking) won't be able to penetrate their servers.
A second model of anonymizing is called "onion routing." Developed by researchers at the US Naval Research Laboratory, Onion Routing is based on the idea of "layering" encrypted messages. Connections are made through machines called onion routers, which allows both the sender and the receiver to remain anonymous. On this account, the network "grid" consists of permanent socket connections. Sequences of routers are defined by the setup, and each router is only known to its immediate neighbors. At each router layer, data is encrypted differently, thus making the data more obscure as the layers deepen. An important difference from basic anonymization is that the business part of the sanitization takes place at the application layer.
Onion routing relies on proxy servers that define sequences of routing nodes. In a sense, one may think of the entire route itself as encapsulated. The onion routing may use any form of encryption and any network protocol so long as the routers agree. The general strategy is that initiating router adds layers to the onion, while each transmitting router peels off a layer, decrypts forwarding information, and sends on what's left. The most important difference from the first model of 'anonymizer' is that onion routing protects the identity of both the sender and receiver - from snooping and from each other. If there's a major vulnerability, it would lie at the endpoints of the communication as network sniffers could conceivably detect initial connections.
A third anonymizing metaphor is called "crowds." Developed by Mike Reiter and Avi Rubin at AT&T Research labs, crowds work by obscuring the actual source of Internet traffic by burying it in the traffic of a "crowd" of users. Given sufficient geographical diversity, individual HTTP requests just seem to blend in with one another.
Crowds uses a proxy server, JONDO, that runs on the users local machine. JONDO communicates with a server called a "blender" to request admission to the crowd. If accepted, the blender serves up a token proxy from the entire crowd at random, and uses that for the identification of the communication. The packets are then routed through the crowd to the destination, thereby obliterating all tracks.
There is less encryption than Onion Routing System because it uses a single symmetric key that is shared by every node on the path. If Crowds has a vulnerability, it is likely to be in the area of traffic analysis and being foiled by executable content (Active X, Java) malware.
A fourth paradigm is Lucent's Personalized Web Assistant. Formerly known as Janus, LPWA was released in 1997. Renamed ProxyMate.com as a start up venture in Spring 1999, the technology sold to NaviPath in May 2000 an Internet access solutions provider, and is no longer supported so far as we know.
LPWA was designed to provide client anonymity and unlinkability between different sites. Unlike the other three services we described, LPWA is "stateless" - i.e., it does not keep internal records of users and aliases. It is designed is such as way that it can recognize returning traffic without retaining lists of associations of aliases and actual identifiers. This feature, the generation of pseudonym aliases, together with the filtering of HTTP header fields, and the use of indirection, where the TCP connection between user and site passes thru proxies, made LPWA an interesting model. Its limitations were in vulnerability to traffic analysis, both in terms of forward tracking and replay attacks.
Our final model is "Safeweb," funded by Voice of America and the
CIA venture firm of In-Q-Tel. Safeweb touts itself as the "Most Widely
used Online Privacy Service in the World." Safeweb began operation in October
2000, and in August 2001 was licensed to PrivaSec. PrivaSec later suspended
its free public access service citing financial constraints in November 2001.
Although no longer available, Safeweb does offer some interesting insights on
the development and implementation of an anonymous service.
Safeweb offers a sense of anonymity through the use of URL encryption, much
like anonymizer.com. Its architecture uses both SSL and JavaScript to encrypt
Web traffic, except that it uses Secure Socket Layer (SSL) or HTTPS.
The URL looks something like:
http://www.interestedsite.com --> https://www.safeweb.com/0/-0/4101/0011
Once the URL is rewritten in the user's browser, an SSL connection to SafeWeb
is established, which then finds the requested website and returns it to the
user.
Another interesting aspect of SafeWebs design was the use of cookies. Cookies
are pieces of text information which the server places on the users hard drive
and allows the server retrieve the information at a later time. Because of the
amounts of information that cookies collect, they are considered very dangerous
to overall security. Safeweb uses a form of cookie generation called the Master
Cookie. The master cookie combines the generic cookie information with Safewebs
proprietary cookie information. Of course this is a potential vulnerability
should the Master Cookie be accessed by unauthorized third parties. Another
vulnerability is traffic analysis. Even though the traffic is encrypted, much
is revealed by the size of the files and packet header contents.
CONCLUSION
Anonymization is the business of obscuring the source and perhaps also the destination of network traffic. In this column, we've introduced you to some of the best-known environments for anonymizing the Internet. Anonymizer.com's simple design makes it very popular. Crowds provides an entirely different approach by blending traffic into streams to make tracing difficult. Onion routing obscures traffic by adding multiple layers of encryption. LPWA and Safeweb are still uniquely different in their own ways. In our laboratory, we developed our own anonymizer, called Anonymator, from which the screen shots in Figures 1-3 were taken. No matter which technology is considered, 'anonymizers' attempt to accomplish the same result of sanitizing packets.
Overall, the systems vary in terms of overall anonymity protection. Safeweb and Anonymizer both offer more in terms of user privacy by rewriting most of the content and suppressing certain codes, including Java and Javascript, but no proof that they offer the user enough protection in terms of connection anonymity. Onion routing and crowds both provide much better protection in terms of connection anonymity. LPWA was designed as a middleman between all the other services, by providing pseudonymity and filtering. Security is a tradeoff between the users ability to use services and the protection developed by those services.
URL PEARLS
As an aside, you may have noticed that we put the term 'anonymizer' in scare quotes throughout this article. According to Lance Cottrell, CEO of Anonymizer.com, the word is actually trademarked by Anonymizer.com, despite the fact that it was a common term used by the networking community prior to Anonymizer.com's existence. To us, this is like trademarking "milk," but they we're not trademark attorneys. In deference to Mr. Cottrell, we put scare quotes around the term whenever it is not associated with his company.
Anonymator, was created in our Cybermedia Rearch Lab as a general experimental platform to test for efficiencies and vulnerabilities in anonymizing technologies. We are indebted to Doina Bein for her bravura performance as lead programmer. At some point in the not-too-distant future we intend to release Anonymator as open-source software. I'll post the notice in a future column.
That said, the following will get you started on your tour through the inner sanctum of anonymization.
1. Anonymizer.com http://www.anonymizer.com
2. Hal Berghel. "Caustic Cookies," Communications of the ACM. Vol.44, No.5, 19-22, May 2001. online preprint at: berghel.net/col-edit/digital_village/apr-01/dv_4-01.html.
3. Hal Berghel. "Hijacking the Web," Communications of the ACM, 45:4
(2002), pp. 23-27. online preprint at:
berghel.net/col-edit/digital_village/apr-02/dv_4-02.html.
4. Hannes Federrath. Privacy, Anonymity and Unobservability in the Internet. http://www.inf.tu-dresden.de/~hf2/anon/
5. Andre Hintz. Fingerprinting Websites using Traffic Analysis. Proceedings of the 2nd Workshop in Privacy Enhancing Technologies, Springer Verlag , April 2002. http://guh.nu/projects/ta/safeweb/
6. David M. Kristol, Eran Gabber , Philip B. Gibbons, Yossi Matias, Alain Mayer. Design and Implementation of the Lucent Personalized Web Assistant (LPWA). Information Sciences Research Center. Bell Laboratories, Lucent Technologies. June 10,1998
7. The Lucent Personalized Web Assistant. Bell Labs Technology Demonstration. See http://www.bell-labs.com/project/lpwa/system.html
8. David Martin and Andrew Schulman. Deanonymizing Users of the SafeWeb Anonymizing Service. Technical Report. 2002-2003. Boston University Computer Science Department, February 2002.
9. Onion Routing. http://www.onion-router.net.
10. Michael K. Reiter and Aviel D. Rubin. Crowds: Anonymity for Web Transactions. AT&T Labs-Research. Technical Report 97-115, DIMACS August 1997. ACM Transactions on Information and System Security.
11. Paul F. Syverson, Michael G. Reed and David M. Goldschlag. Anonymous Connections and Onion Routing. Naval Research Lab. June 2, 1997. http://citeseer.nj.nec.com/syverson97anonymous.html